Data view for LLM pre-training
Mar 1, 2023 00:00 · 474 words · 3 minute read
In this blog, we aims to provide a˜ data’s view to research the emergence ability of large language model(LLM), and provide some point for NLP community to reproduce the GPT-3 or PaLM easily.
Abstract
Large language model have a most powerful to solve the nature language tasks, not only summerization or text classification. Recent research show the LLM have much emergence ability when the model’s size arrive a trade-off line. However, the LLM shown us the emergence model like GPT-3 and PaLM does’t release public, the reproduce of NLP community like OPT, GLM and BLOOM even have the similar size have a long way to reach these.In this post, we aims to get a survey for this fundamental model producing methods to anylisis the reproductions' shortage and provide a good way to reproduce these model so clearly.
大型语言模型具有最强大的解决自然语言任务的能力,而不仅仅是求和或文本分类。最近的研究表明,当模型的大小到达折衷线时,LLM 具有很强的涌现能力。然而,LLM 向我们展示了像 GPT-3 和 PaLM 这样的涌现模型并没有公开发布,像 OPT、GLM 和 BLOOM 这样的 NLP 社区的复制即使有类似的规模也有很长的路要走。在这篇文章中,我们旨在对这种基本的模型制作方法进行调查,以解决复制品的不足,并提供一种将这些模型如此清晰地复制的好方法。
Instruction
通用人工智能一直以来都是研究人员的研究热点,并有着前赴后继的研究人员投入到这类研究中。在2022年的时间点中,人工智能已经可以辅助人类进行诸如订票,写文章,作为客服回答顾客的问题等简单的工作,但是通俗意义下,人们认为其距离通用人工智能仍然有一定程度的距离(即便在此期间,openai以及谷歌的研究人员发现极大的自回归语言模型可能会存在推理【COT相关论文】以及自我意识【推特】的行为,但是都没有引起当时研究界的重视)。在2022年ChatGPT发布之后,为研究人员实现强人工智能(通用人工智能)提供了一条可以实现的道路。
ChatGPt是由OpenAI所开发的InstructGPT继续开发的聊天机器人,其在刚刚发布的一个月内就获得了超过一百万的用户数量。人们惊异于chatgpt对于人类语言的理解能力以及对语言的组织能力,对于任意的问题,chatgpt可以精确的识别用户的意图并给出相对较为准确的答案,其强大一图识别能力是之前的人工智能所不具备的。虽然chatgpt具体的细节并未给出,但是从openai给出的信息中我们可以得到几个关键的信息,即大规模预训练语言模型,自微调学习以及人在回路学习。目前一个简单的共识为,针对预训练任务的训练(GPT 系列采用的是自回归语言建模任务)不仅使模型学习了相当多的知识, 同时还学习到了相对基础的推理能力,自微调算法以及人在回路学习方法使模型学会如何识别用户的意图以及如何释放之前学习到的知识。因此,构建该类通用人工智能的技术中,基础模型的构建与后期学习同样重要。
如前所述,大规模预训练语言模型模型是构建此类通用人工智能的基础与前提,但是构建高效高质量的大规模预训练语言模型需要海量的数据,高额的计算量以及充分的技术储备。虽然目前通用人工智能的训练相当火爆,但是并没有文章系统性的调查目前NLP社区中的大规模预训练语言模型的研究现状与进展。因此,本文从数据,架构,以及评测等多个角度较为系统的调查了较为流行的几个大规模预训练语言模型,来汇总目前大规模预训练语言模型相关的从数据预处理,模型架构选择以及最终的大模型的部分性能对比,以分析大规模预训练模型后续的能力初期来源。
Fundational model pretraining data
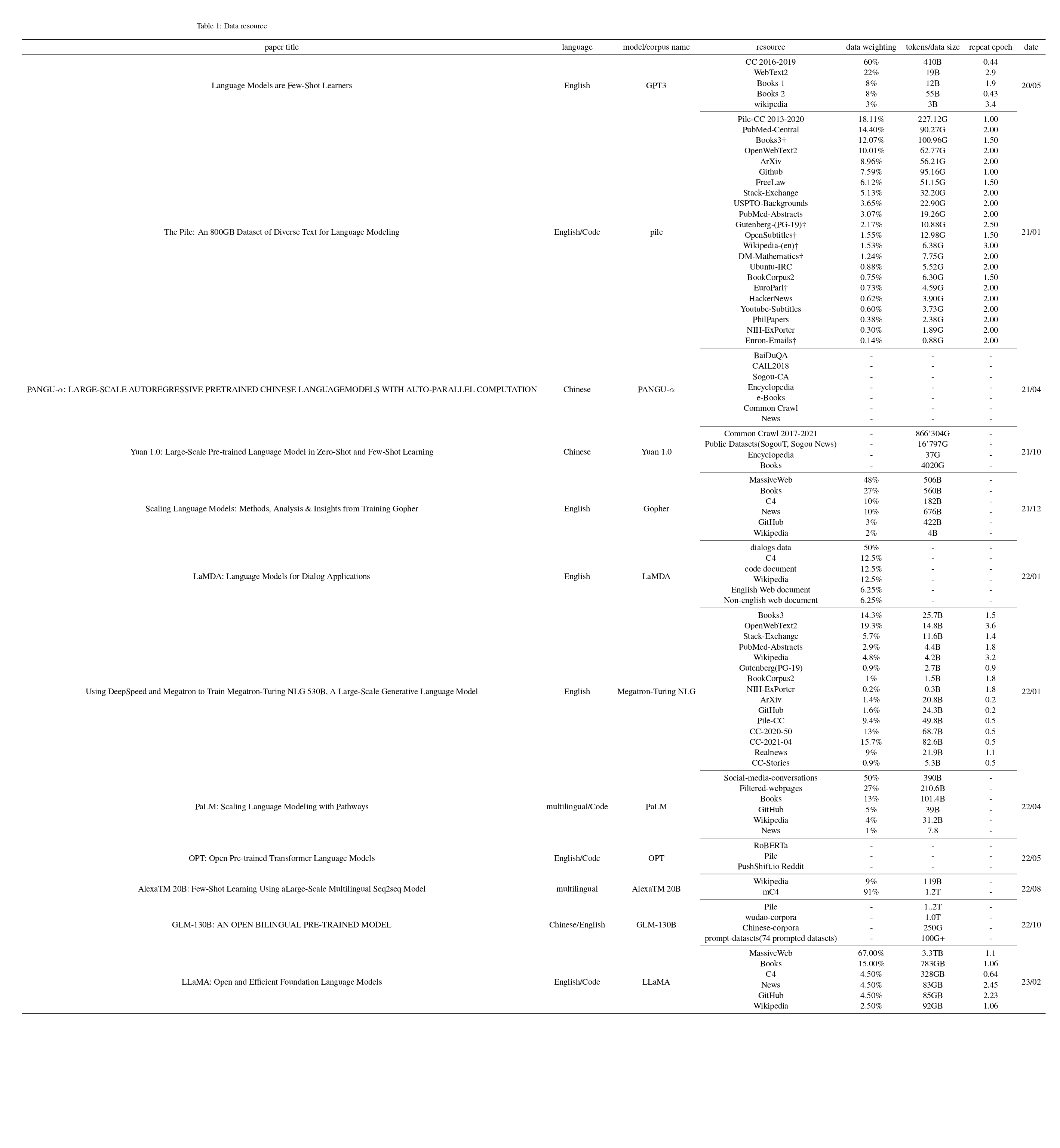
数据是知识的载体,也是是大规模预训练模型训练的基础。数据的质量一定程度上决定大规模预训练模型的效果以及未来将会释放出的突显能力。一个供给给大规模预训练语言模型所使用的语料通常要包含几种基础的属性,包括数量,多样性与高质量。图x中包含几种大规模预训练语言模型所采用的预训练语料的来源,数量,以及所公布的在pile数据集中的困惑度(在一定程度上代表语料质量的高低,但是不绝对)。
-
数据的重要性
”Garbage in, garbage out.“
-
数据来源及其收集
- 绘制了一张包含主流预训练模型的数据来源表,目前所有的数据可以认为全部来自于互联网,但是根据其质量以及处理方式我们可以大致分为互联网文本与人工标注文本,虽然后者可以看作前者的子集,但是人工标注文本见4,是经过精心设计的数据集,其相对高但是数量有限,在互联网文本中,也存在高质量文本来源,这一部分的特殊处理也有利于研究人员补充较高质量的文本,但是其高质量文本仍然相对较少,仍需要互联网文本的通用处理来补充其数量与多样性。
- 大部分全网通用互联网文本数据集来自common crawl,common crawl是一个开源爬虫项目,其主要目的是爬取针目前整个互联网的信息以提供NLP社区进行使用与研究,common crawl存在两种组织形式,某些研究人员采用WET形式进一步预处理后补充预训练语料,另一部分研究人员认为WET可能会引入模版等噪音,因此选用WARC格式。目前已知的根据common crawl进行处理的公开数据集包括pile cc,c4,yuan1.0等。
- 虽然整个互联网数据十分巨大,但是从整个互联网数据中提取高质量的数据集实际上是相当困难的。实际上,人类的高质量文本通常集中在几个巨头【谷歌,维基百科,arxiv,pubmud, freelaw等】或者较为官方【各个国家,地区,组织的官方网站】的几个网站中,针对特定网站进行爬取是目前大规模预训练语料的一个十分重要的补充来源。与全网互联网数据相比,这一部分网站或者数据集的语料比较清洁,形式较固定,一般一类网站通常具有一定的模版形式,便于研究人员进一步的清洗与处理,可以通过较少的操作获得更加高质量的文本;知识性较强,百科,论文等信息可以认为是人类知识的载体,有利于模型学习建模人类归纳性知识;可信度较高,政府公文,法律文书,出版物等需要人工进行审核校验,通常代表了一个领域内较为可信的信息。
- 另外,NLP研究人员在长久的NLP研究中提出了大量的任务,包括但不限制于推理任务,问答任务以及很多的生成任务,这一部分数据集进行统一格式后也是一个较大的数据来源,具体有ROOTs(bloom所用数据集),FLAN,ExT5等。
预训练数据的来源直接关系到语料的多样性。不同来源的语料往往存在不同的题材,不同的格式以及不同的组织方式,补充不同来源的数据往往可以很好的提升模型的鲁棒性与泛化性,图中统计了目前部分主流的大规模预训练模型训练过程中所引入的数据来源,从图中我们可以发现,目前的大规模预训练语料主要存在两个来源,其一是互联网数据的爬取,另一部分是开源NLP数据集。
互联网作为人类信息交换的重要方式,在长久的历史发展中积累了巨量的信息。根据谷歌公司CEO Eric Schmidt 预计,整个互联网数据数量高达5000 PB1,
然而如何获取这一份数据是一项巨大的挑战。受益于互联网爬虫计划common crawl2的开展,研究人员可以更加便利的收集网络中的数据,并将精力集中于数据处理阶段。common crawl是一项开放网络爬虫的数据存储库的开源项目,其爬取并保存了自2013年以来从开放互联网中爬取的各种数据。其主要包括两类,一类是保存的原始数据(warc格式)另一类是简单将html格式中的文本进行抽取出来的文本数据(wet格式)。一般认为,warc格式的数据中保留了网站原本的结构与布局,其内容较为丰富与完善,但是缺点是冗余信息较多,抽取与处理较为复杂,而wet格式是经过简单文本抽取的文本数据,丢失了较多的信息,但是处理起来较为简单,另外A.Askell等人3认为,wet文本可能会讲框架或者布局中的数据掺杂在正文中,这将破坏正文的连贯性与一致性,从而影响模型对于语言建模任务的学习。
虽然common crawl中包含了大量的数据,但是由于其数据量大并且其质量不对等导致对于大规模预训练语言模型的训练具有不可控的影响,因此,之前的几份工作都表示引入了更多的预处理数据,或者针对指定的网站的数据进行定向收集。例如,在Tom etc.4提到,除了预处理common crawl的数据外,他们同样添加了高质量图书数据集Books1,Books2以及维基百科等作为高质量数据的补充,同时也作为其训练质量分类器的训练数据。Pile5除了common crawl收集的数据外,还收集了将近21个站点的数据,其中包括学术论文网站pubmud,arxiv,代码共享平台github,编程交流平台stack exchange,预处理图书数据集BookCorpus 2、Books3、OpenWebText2,以及其他相关高质量数据集等。悟道6同样的采用了大量的网络语料,与前面不同的是,其主要筛选中文语料,并对中文字符少于10个的网页进行了丢弃。
另外,经过我们的调查发现,Pile5作为处理质量较高的数据集在开源后被广泛使用,后续的一系列工作789倾向于在与训练语料中加入Pile或者Pile CC,以节省数据处理的时间,同时加入部分更新时间戳下的Common Crwal语料,以保证模型的质量与时效性。
-
互联网文本数据预处理
-
这里的数据预处理主要是互联网数据的抽取与清洗/转换,同时也包含特殊网站的预训练语料的处理
-
互联网中的信息大多数以HTML的形式进行组织,需要从html转换为txt形式,才能给模型进行训练,该任务存在很多方法:
-
解析前端语法树,基于其dom tree对数据进行解析,这种方法通常都是对特定网站进行处理,针对网站攥写指定的解析方式,这种方式预处理最彻底,但是其对所有网页编写规则并不现实
-
针对通用网页的处理,目前的方式存在两种,
- 直接删除tag,在文本层面对数据进行去重,这一部分将着重在下一部分通用文本质量筛选中进行介绍【句子层面】
- 以一种较为通用的形式,对html网页进行解析,将html数据转换为markdown或者其他形式。
-
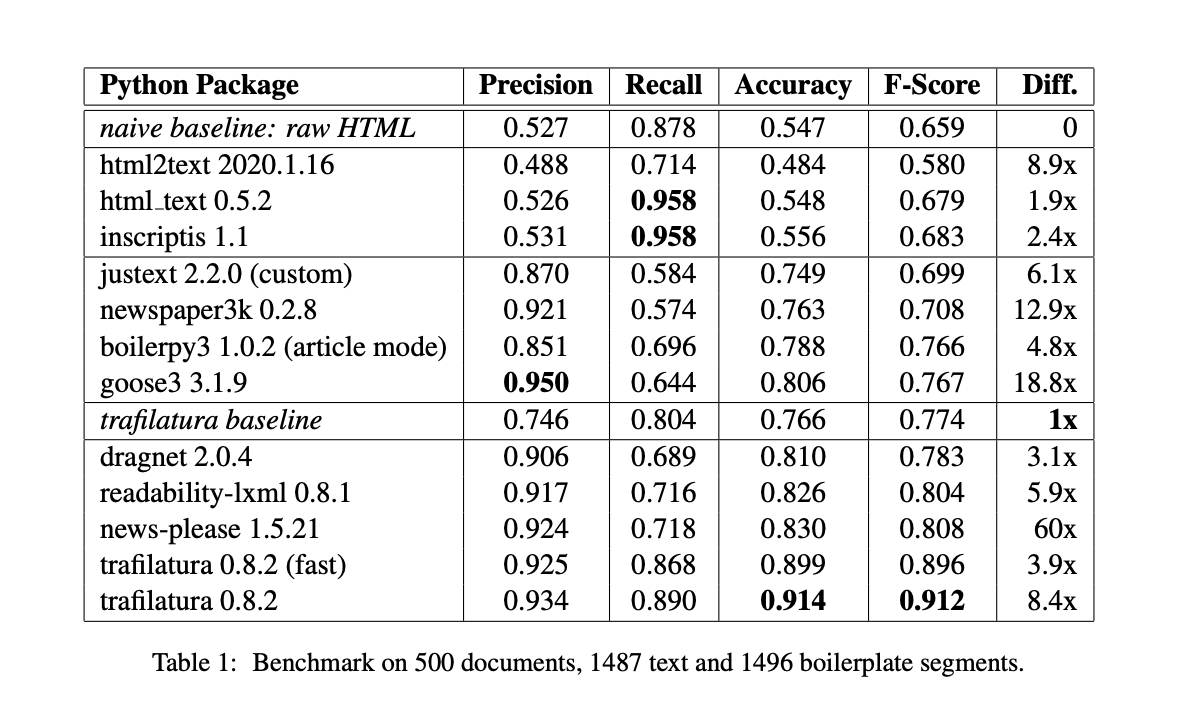
目前存在大量的工作与开源项目来尝试从通用的网页中提取数据:
-
2.3中提到的部分网站,其数据组织形式并不是单纯的采用html,某些采用letax或者其他格式,部分工作保留其格式,将其转换为mark-style的形式,以较小的tag引入更多的信息。
-
数据处理方面主要存在两个分解的问题:数据处理方法以及数据处理流程,之前的工作说明了其对于大规模预训练语料的处理流程,整体都可以分为三个模块,对于网络信息的抽取与转换,对于数据的评估与清洗,对于数据的去重。
由于网页中的信息一般采用html语言并经过浏览器的解析被人们所看到,也就是说,一般来说,被我们直接爬取的信息以html的形式保存在原始数据汇总(在Common crawl中以warc的形式存储在数据库中),html语言对于人类语言来说存在非常多用于排版的tag从而带来较多的信息冗余。基于这个原因,一部分工作采用wet格式【一种common crawl 从网页中抽取文本组成的格式】来进行进一步的预处理,例如GPT-34的原始版本训练时采用WET格式,后续对其进行了文档级别的筛选,T510采用WET格式预处理的方式比较严格,其采用了一系列启发性的操作,例如关键字匹配,关键语法匹配等。CC Net 同样采用WET格式进行文档级别的筛选,但是该类问题的处理方式丢失了数据的格式,仅仅保留了文本。因此,另外一部分工作采用WARC格式来进行下一部分的与处理。Pile5认为,采用WET格式数据将会造成文档内模版数据无法删除,即便采用去重算法以及关键字匹配算法,处理后的数据质量仍然较低。其实验了几种提取工具,由于其准确丢弃率较高,因此采用jusText11用以处理WARC格式内部的模版文件,并提取网页模版内部的文本数据。MT-NLG7 也延续了这一操作。
对于特殊高质量语料的转换处理,该部分存在几种情况,一种是挑选出的高质量网站爬取的数据,由于该部分网站模式单一,可以采用固定的几种提取方式将正文直接提取出来,对于非html格式组织的数据,例如pile5中所引入的arxiv的Tex 格式与Pubmed Central中按照JATS格式组织的论文将通过pandoc12进行处理为markdown形式,该格式保留了文本的原始结构特征,其数据的表达能力有所提升的同时防止大量无关标签的引入导致数据的质量下降。类似于zhihu或者 Stack Exchange网站中的带有明显「问题,答案」结构的数据可以对其进行结构化处理,例如加入Q:\n\n A:\n\n来将其转化为带有QA结构的数据。对于已经预处理好的数据,或者存在开源版本特定算法的数据,例如wiki ,大部分工作认为可以直接将其引入到预训练语料当中,这一部分数据其质量是最高的,所蕴含的知识相对于其他语料也较多,因此,该部分语料在训练过程中通常需要上采样,以增加模型学习高质量语料的比例
-
指令预训练数据预处理
- 来源是NLP中的范式迁移,从T5统一范式到ExT5尝试在T5架构训练中引入下游任务的数据
- 来自于InstructGTP中的观点显示,除了上述统一范式的指令预训练之外,可以引入人类的指令进行微调,这种训练方式可以更好的对齐人类的要求。
- 目前已知的开源工作包括PromptSource, ROOTS【bloom训练使用】
- 采用1类的工作包括ExT5,FLAN,Bloom,Bloomz,OPT-IML,GLM的一部分训练语料
- 采用2类的工作包括InstructGPT【ChatGPT】,moss,问心一言【未发布开源】等
-
数据质量控制
-
数据质量控制住要从一下四个部分进行考虑,这一部分主要是从上面收集到的语料中进一步清洗与筛查,进一步提升数据的质量。
-
通用数据筛选
从common crawl中获取的数据质量较低,需要进一步的进行筛选
1. C4 引入一些规则来进行筛选处理
-
gpt-3中采用简单的线性分类器进行筛选,在阈值选择上采用帕累托分布进行采样。
-
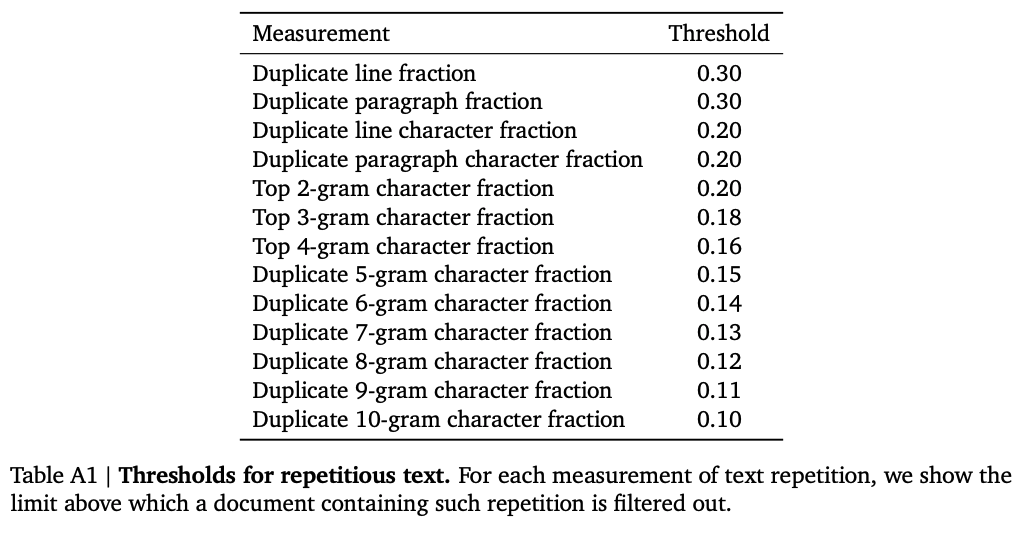
MissiveText引入了更多的更复杂的筛选,包括文本长度要求,符号文字比,停用词比例等。
-
-
数据质量筛选
-
数据安全性筛选
-
数据重复性筛选
-
-
数据质量评价
- 数据的质量可以分为语句的质量以及语料的质量
- 语句的质量
- 流畅性
- formality 格式化
- objectivity 客观性
- Conciseness 简明性
- formality or jargon 专业性
- 语料的质量/性质
- 数量
- Diversity 多样性【语言的多样性,主题的多样性】
- bias 偏见
- fairness 公平性
对预处理数据的评价标准是十分难以鉴别的,在没有训练,测评之前,我们并不知道一个真正优质的,鲁棒的,无偏差的,高知识的模型需要何种数据。而理论上高质量且多样的数据将会训练出一个更好的模型。目前的大规模语言模型通常情况下采用T级别的语料进行训练,LLama13等工作表明,更多的数据有利于模型对于语言的学习。ExT5,FLAN等工作表示引入部分下游任务有利于模型性能的提升,而很多的已知的工作表示,更多的来源以及更精细化的处理可能会给语言模型带来更好的性能。因此,对于前期数据质量的评定在一定程度上也可以反映出训练后模型的性能。当前,研究人员主要集中在数据的多样性与基于模型的数据质量对于预训练的数据进行评价。
对于数据的多样性,其主要表现为数据来源的多样,语言的多样,主题的多样以及表达方式的多样, 大部分工作都选择采用多来源的数据集进行训练,一方面,多来源的数据可以收集尽可能多的数据,补充数据的数量,另一方面,多个来源的数据往往会有不同的主题或者表达方式,往往其多样性也可以得到保证。为了衡量或者评估数据集的多样性,部分工作采用topic model的方式,希望判断数据集主题的多样性来对数据集进行分析,PaLM14采用Hierarchical topic modeling的方式,对数据集进行评估,Pile在Pilecc中训练了一个16gram的topic model 作为基准,以此衡量各个子数据集的多样性。
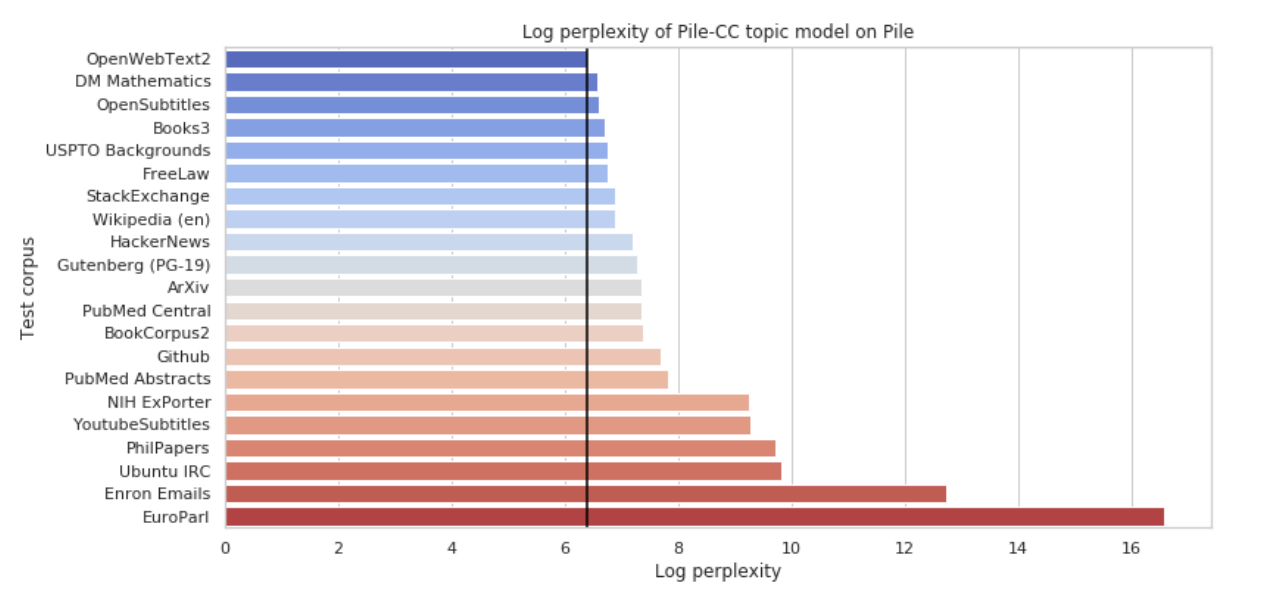
对于数据集的质量,目前并没有较好的评估方案。大部分的工作采用另一个语言模型来计算在该数据集上的困惑度。例如,pile在其论文中针对GPT-2与GPT-3对pile数据集的困惑度,后续的部分工作为了证明模型的效果,同样的在pile数据集中验证困惑度,一方面通过GPT-3证明其数据具有较为优质的质量【符合模型生成或者训练的需要】,另一方面模型通过数据也可以验证其效果,但是该方法存在弊端,即无法证明数据与模型是否最优以及如何达到最优。另外,根据【引用】所实验,困惑度相对于中文可能并不是一个很优质的指标,需要寻找另外的一个指标来对中文的质量进行分类。
另外,pile5同样的对于各个子数据进行了13-gram的同一性检测,大部分的13-gram重复为格式文件,html符号,网站的评论或者正文模版信息。这些信息不仅仅对于数据质量存在影响,可能需要后续工作提出更好的数据预处理方案。
另外,更多的验证包含数据的偏见,毒性等可以采用采用计算协同性质的方法来进行评估14。
Refenrence
-
https://www.easytechjunkie.com/how-big-is-the-internet.htm#:~:text=That's%20over%205%20billion%20gigabytes%20of%20data%2C%20or%205%20trillion%20megabytes. ↩︎
-
A. Askell等, 《A General Language Assistant as a Laboratory for Alignment》. arXiv, 2021年12月9日. 见于: 2023年3月6日. [在线]. 载于: http://arxiv.org/abs/2112.00861 ↩︎
-
T. B. Brown等, 《Language Models are Few-Shot Learners》. arXiv, 2020年7月22日. [在线]. 载于: http://arxiv.org/abs/2005.14165 ↩︎
-
L. Gao等, 《The Pile: An 800GB Dataset of Diverse Text for Language Modeling》. arXiv, 2020年12月31日. [在线]. 载于: http://arxiv.org/abs/2101.00027 ↩︎
-
《WuDaoCorpora: A super large-scale Chinese corpora for pre-training language models - ScienceDirect》. https://www.sciencedirect.com/science/article/pii/S2666651021000152?ref=pdf_download&fr=RR-2&rr=7a29c845ab86f963 ↩︎
-
S. Smith等, 《Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model》. arXiv, 2022年2月4日. 见于: 2023年3月4日. [在线]. 载于: http://arxiv.org/abs/2201.11990 ↩︎
-
S. Black等, 《GPT-NeoX-20B: An Open-Source Autoregressive Language Model》. arXiv, 2022年4月14日. 见于: 2023年3月4日. [在线]. 载于: http://arxiv.org/abs/2204.06745 ↩︎
-
S. Zhang等, 《OPT: Open Pre-trained Transformer Language Models》. arXiv, 2022年6月21日. 见于: 2023年3月4日. [在线]. 载于: http://arxiv.org/abs/2205.01068 ↩︎
-
C. Raffel等, 《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》. arXiv, 2020年7月28日. 见于: 2023年3月6日. [在线]. 载于: http://arxiv.org/abs/1910.10683] ↩︎
-
I. Endrédy和A. Novák, 《More Effective Boilerplate Removal-the GoldMiner Algorithm》, Polibits, 期 48, 页 79–83, 12月 2013. ↩︎
-
R. Thoppilan等, 《LaMDA: Language Models for Dialog Applications》. arXiv, 2022年2月10日. 见于: 2023年3月6日. [在线]. 载于: http://arxiv.org/abs/2201.08239 ↩︎
-
A. Chowdhery等, 《PaLM: Scaling Language Modeling with Pathways》. arXiv, 2022年10月5日. 见于: 2023年3月6日. [在线]. 载于: http://arxiv.org/abs/2204.02311 ↩︎